
【機械学習】アニメ画像を判別してみた!
どうも!ヒグッティ(ヒグッティ@システムエンジニア)です!
今回は機械学習でアニメ画像の判別について書いていきます。機械学習は全くの初心者が判別モデルを作成するまでにやったことや実際のソースを備忘録がてら記載します。アニメ画像はリゼロのレムとこの美のみずきを使っています。
目次
やったこと
- 基本的な考えの理解
- ソースを書いてみる
- 実際に判別してみる
環境
- google colaboratory
- keras
機械学習の考え方
今回は画像を判別するためだけにフォーカスしていきます。損失関数や畳み込み処理も画像分類に偏っています。
考え方としては学習データの解析、特徴の算出、算出結果と正解を比較、誤差によってパラメータを更新、これの繰り返しです。正直、中身や考え方を知らなくてもフレームワークが勝手にやってくれるので、簡単にできちゃいます。しかし!!エンジニアたるもの中身が気になりますよね!?今回はその中身もできるだけかみ砕いて説明していきます。
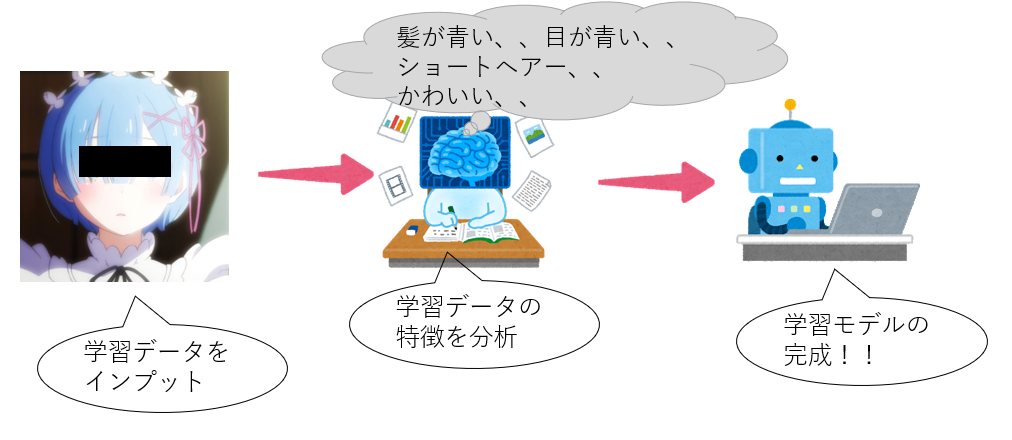
全体の流れ
私は以下のように機械学習について学習しました。本記事もこの流れで説明します。
- どうやって画像を判別、分類するのか?
- ソースを書いて動かす
- ソフトマックス関数
- 活性化関数
- 畳み込み処理
- MaxPooling
- 最適化、損失関数
どうやって画像を判別、分類するのか?
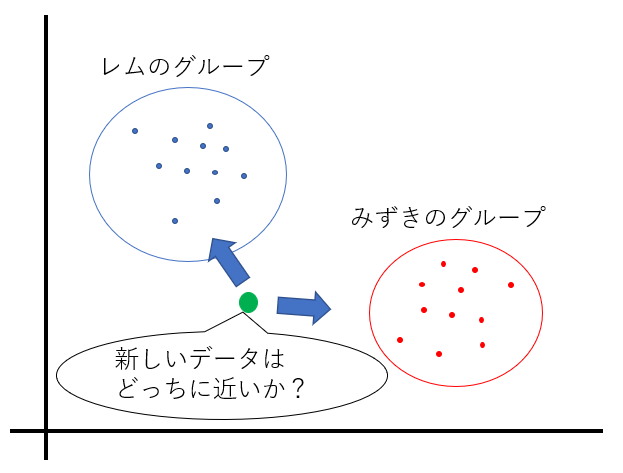
私が機械学習で画像を判別したい思いましたが、全く想像がつきませんでした。まず、分類のイメージは「どのグループに最も近いか?」を探すことと思っています。今回で言うとレム、みずきというグループがあり、学習によってグループ分けします。その後、未知の画像が来た時、どっちのグループに近いかモデルに判定させるという感じです。
ソースを書いて動かしてみよう!
まずは動くものを作ってみましょう!今回はgoogle colaboratoryで動かします。ソースは以下のyoutubeを参考にさせていただいております。
【完全版】この動画1本で機械学習実装(Python)の基礎を習得!忙しい人のための速習コース 人工知能で毒キノコを判別しよう – #1 デモと環境構築以下は学習のソースです。最後にモデルを作成しています。
from keras.backend import categorical_crossentropy
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras.layers import Conv2D, MaxPooling2D, Flatten
from keras.preprocessing.image import ImageDataGenerator
model = Sequential()
model.add(Conv2D(64,(3,3), input_shape=(64,64,3)))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(64,(3,3)))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(256))
model.add(Activation("relu"))
model.add(Dense(2))
model.add(Activation("softmax"))
model.compile(
optimizer="adam",
loss="categorical_crossentropy",
metrics=["accuracy"])
train_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
"/content/drive/MyDrive/GAN_img/sample/train",
target_size=(64,64),batch_size=10
)
dation_generator = test_datagen.flow_from_directory(
"/content/drive/MyDrive/GAN_img/sample/validation",
target_size=(64,64),batch_size=10
)
model.fit_generator(
train_generator,
epochs=10,
steps_per_epoch=3,
validation_data=dation_generator,
validation_steps=2)
model.save('./remVSmizu2model.h5')以下は作成したモデルを使って、画像を判別するソースです。
import sys
from PIL import Image
from keras.models import load_model
import numpy as np
import matplotlib.pyplot as plt
import glob
image = Image.open('/content/drive/MyDrive/GAN_img/sample/bunrui/mizu_11.png')
image = image.resize((64,64))
print("識別に使う画像")
plt.imshow(image)
model = load_model("/content/remVSmizu2model.h5")
np_image = np.array(image)
np_image = np_image / 255
np_image = np_image[np.newaxis,:,:,:3]
res = model.predict(np_image)
print(res)
if(res[0][0] > res[0][1]):
print("mizukiです!")
else:
print("remです!")
今回は学習用データを「/content/drive/MyDrive/GAN_img/sample/train」に格納しています。「/content/drive/MyDrive/GAN_img/sample/train」の下に「mizuki」、「rem」のディレクトリを作成し、その下に学習用の画像を入れています。
学習のソースを動かしてみた
学習用のソースを動かしてモデルを作ります!
さっそくエラー発生しました、、、
Found 40 images belonging to 3 classes.
Found 14 images belonging to 3 classes.
/usr/local/lib/python3.7/dist-packages/ipykernel_launcher.py:40: UserWarning: `Model.fit_generator` is deprecated and will be removed in a future version. Please use `Model.fit`, which supports generators.
Epoch 1/10
---------------------------------------------------------------------------
InvalidArgumentError Traceback (most recent call last)
<ipython-input-11-4fcc412ac2fb> in <module>()
38 steps_per_epoch=3,
39 validation_data=dation_generator,
---> 40 validation_steps=2)
41 model.save('./remVSmizu2model.h5')
2 frames
/usr/local/lib/python3.7/dist-packages/tensorflow/python/eager/execute.py in quick_execute(op_name, num_outputs, inputs, attrs, ctx, name)
53 ctx.ensure_initialized()
54 tensors = pywrap_tfe.TFE_Py_Execute(ctx._handle, device_name, op_name,
---> 55 inputs, attrs, num_outputs)
56 except core._NotOkStatusException as e:
57 if name is not None:
InvalidArgumentError: Graph execution error:このエラーだけで2時間は格闘してましたwww、、結局、「Found 40 images belonging to 3 classes.」からわかりました。今回はレムとみずきの2つに分類したいのになぜか3つに分けようとしている、、、
そう!これがヒントになりました!!原因は「/content/drive/MyDrive/GAN_img/sample/train」、「/content/drive/MyDrive/GAN_img/sample/validation」の下に変なディレクトリがありました。

「.ipynb_checkpoints」が犯人でした。このディレクトリは消して問題ないようです。以下のコマンドをgoogle colaboratory上で実行すればディレクトリが消せます。
!rm -fr /content/drive/MyDrive/GAN_img/sample/train/.ipynb_checkpoints
!rm -fr /content/drive/MyDrive/GAN_img/sample/validation/.ipynb_checkpoints再実行すると、、
Found 40 images belonging to 2 classes.
Found 14 images belonging to 2 classes.
/usr/local/lib/python3.7/dist-packages/ipykernel_launcher.py:40: UserWarning: `Model.fit_generator` is deprecated and will be removed in a future version. Please use `Model.fit`, which supports generators.
Epoch 1/10
3/3 [==============================] - 1s 281ms/step - loss: 1.3890 - accuracy: 0.3667 - val_loss: 0.6757 - val_accuracy: 0.6429
Epoch 2/10
3/3 [==============================] - 1s 199ms/step - loss: 0.7608 - accuracy: 0.5000 - val_loss: 0.6327 - val_accuracy: 0.6429
Epoch 3/10
3/3 [==============================] - 1s 198ms/step - loss: 0.6044 - accuracy: 0.7667 - val_loss: 0.5852 - val_accuracy: 0.7143
Epoch 4/10
3/3 [==============================] - 1s 192ms/step - loss: 0.4913 - accuracy: 0.8333 - val_loss: 0.4817 - val_accuracy: 0.9286
Epoch 5/10
3/3 [==============================] - 1s 192ms/step - loss: 0.3257 - accuracy: 0.9667 - val_loss: 0.4530 - val_accuracy: 0.7143
Epoch 6/10
3/3 [==============================] - 1s 198ms/step - loss: 0.5637 - accuracy: 0.7667 - val_loss: 0.8162 - val_accuracy: 0.5000
Epoch 7/10
3/3 [==============================] - 1s 201ms/step - loss: 0.4463 - accuracy: 0.8333 - val_loss: 0.3487 - val_accuracy: 0.7857
Epoch 8/10
3/3 [==============================] - 1s 196ms/step - loss: 0.1631 - accuracy: 0.9333 - val_loss: 0.4427 - val_accuracy: 0.7143
Epoch 9/10
3/3 [==============================] - 1s 191ms/step - loss: 0.1826 - accuracy: 0.9667 - val_loss: 0.2596 - val_accuracy: 0.9286
Epoch 10/10
3/3 [==============================] - 1s 197ms/step - loss: 0.1066 - accuracy: 1.0000 - val_loss: 0.2867 - val_accuracy: 0.8571正常完了!学習結果も「accuracy: 1.0000」となりました!正解率100%、、過学習か、、まぁ今回は気にしません!
ちなみにこれが学習で使った画像の一部です。

判定用のソースを動かしてみる
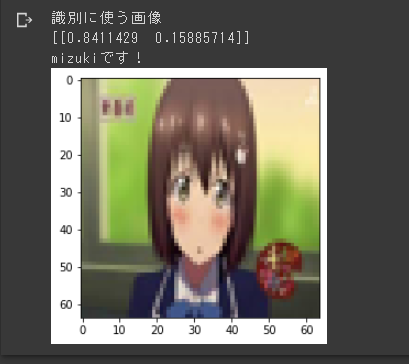
作成したモデルを動かしたときに用いた画像と結果です。ちゃんと「みずき」と判定してくれましたね!
[[0.8411429 0.15885714]]というのは、みずきの可能性が84%、レムの可能性が15%という意味です。用いている画像が荒いのは64×64pixelに変換してから読み込ませているからです。
何をしているか考える
実際に作るだけなら正直2~3時間あれば、できちゃいます。フレームワーク側でほとんどやってくれているので意識しなくてもできてしまいます。これからは作成した学習用のソースを元に何をしているか見ていきます。
重要なのは、以下の部分です。
model = Sequential()
model.add(Conv2D(64,(3,3), input_shape=(64,64,3)))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(64,(3,3)))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(256))
model.add(Activation("relu"))
model.add(Dense(2))
model.add(Activation("softmax"))
model.compile(
optimizer="adam",
loss="categorical_crossentropy",
metrics=["accuracy"])そもそも画像とは?
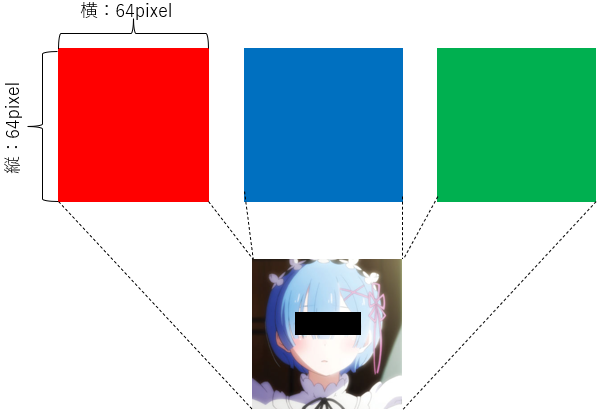
画像はRed(赤)、Green(緑)、Blue(青)の3つのデータを合わせて一つの色を表現しています。各色は0~255で表されます。また色の情報と縦、横のサイズ(pixel)で構成されています。
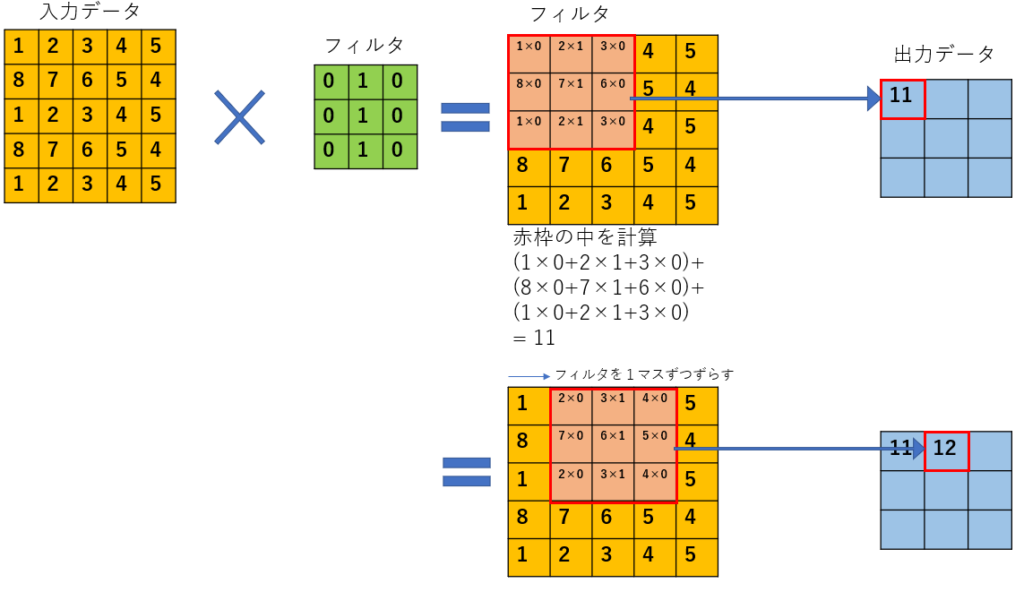
畳み込み処理
ソースで言うとこの箇所が何をしているかを見ていきます。
model.add(Conv2D(64,(3,3), input_shape=(64,64,3)))まずは「Conv2D(64,(3,3), input_shape=(64,64,3))」に注目します。この意味は、64pixel×64pixel×3色の画像データを入力( input_shape=(64,64,3) )とし3×3のフィルターを64枚用意し畳み込み処理(Conv2D(64,(3,3))をします。
イメージ的には以下です。入力データとフィルタの掛け算です。フィルタはフレームワーク側で値を決めてくれます。このフィルタは64枚用意されますので、この処理での出力データは64枚の画像データということになりましす。
活性化関数
次の行を見ていきます。これは活性化関数の処理です。
model.add(Activation("relu"))活性化関数は畳み込み処理などで取得した出力データを次の処理に出力するために使います。わかりづらいので以下を見てください。
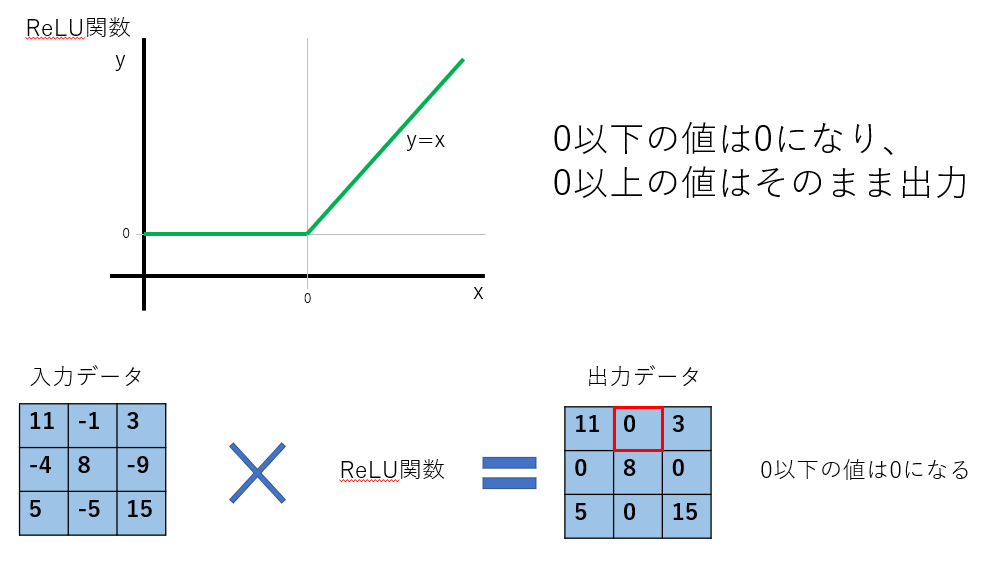
特徴をはっきりさせるために使います。画像の分類をするときの活性化関数はReLUと覚えておきましょう。
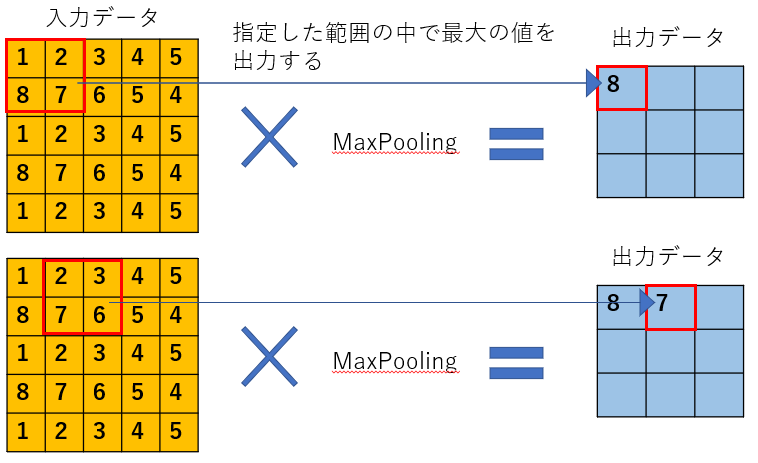
マックスポーリング(MaxPooling)
次は以下の行を見ていきます。
model.add(MaxPooling2D(pool_size=(2,2)))MaxPoolingは畳み込み処理の直後に実施することが多い処理です。役割としては、畳み込み処理で抽出した特徴からさらに抽出するイメージです。画像によっては取り出した特徴が少し異なるだけで、その画像が判別ができなくなる恐れがあります。それを普遍的に判別できるように、特徴を薄めるような効果があります(過学習の防止に役立つ)。
結合層
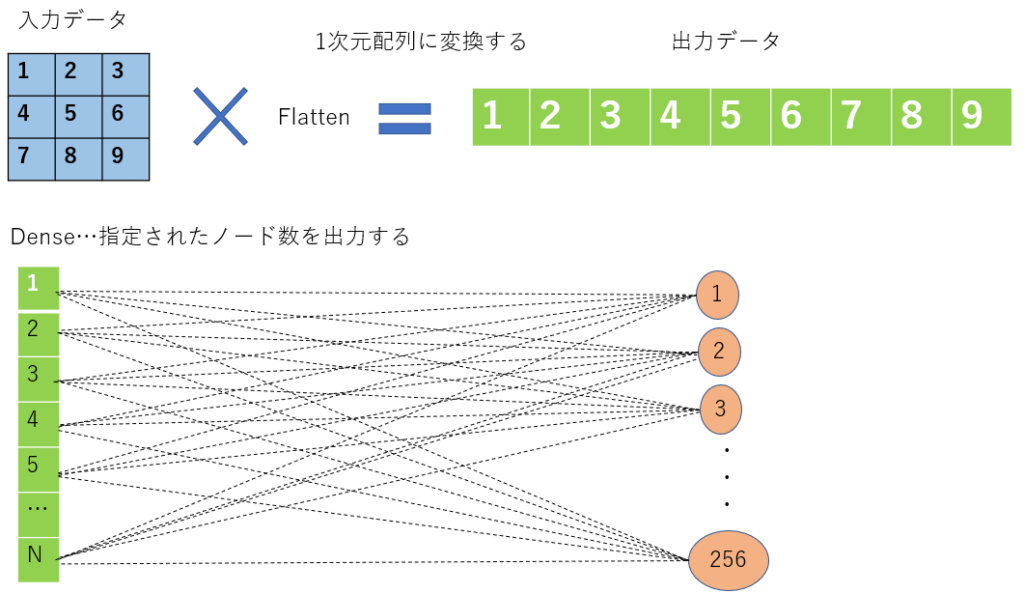
以下の行を見ていきます。Flatten、Denseは今までの入力データや抽出したデータを結合する役割があります。
model.add(Flatten())
model.add(Dense(256))Flattenは入力データを1次元配列に直します。Denseは指定した出力数(ノード)に出力します。にこれは以下のイメージです。
ソフトマックス関数
以下の行を見ていきます。活性化関数の一つであるソフトマックス関数についてです。今まで算出した特徴を分類するための役割がある私は思っています。
model.add(Activation("softmax"))ソフトマックス関数とは、分類したい対象が3つ以上の時に利用します(2つのときも利用可能)。例えば、レム、ラム、みずきに分けたいときはソフトマックス関数を利用した方がよいです。
この関数の良いところは入力値に対し、出力値の合計が0~1で出力します。つまり、レムの画像を入力値とした場合、出力値としてレムである可能性の%を出力します。レムの可能性90%!!ラムの可能性5%!みずきの可能性5%的な感じです。
損失関数
以下の行を見ていきます。 損失関数とは正解値と予測値を比較して誤差がどのくらいあるかを算出する方法です。今回はクロスエントロピーを利用します。
クロスエントロピーとは、予測した確率(学習によって算出した確率)と実際の確率(実際の正解)がどのくらい近いかを出力します。確率が近い場合、損失は小さくなり、確率が異なる場合、損失は大きくなります。
例えば、レムの画像を入力値とした場合、実際の確率は「レムが100%、みずきが0%」です。学習によって算出した確率が「 レムが10%、みずきが90%」だとすると明らかに結果がずれています。この時クロスエントロピーで誤差を計算すると損失が大きくなります。損失が大きい場合、パラメータを更新し、畳み込み処理から再度、学習を繰り返します。この損失が最小になるように内部のパラメータを更新し続けます。
loss="categorical_crossentropy",最適化
以下の行を見ていきます。最適化はoptimizerとも呼ばれます。最適化とは損失関数で取得した誤差を元にその誤差が小さくなるように、利用しているパラメータを更新することです。
optimizer="adam",今回はAdamを利用しています。Adamとは最急降下法の進化バージョンと考えてください。ここでは最急降下法について説明します。
最急降下法は最も代表的な最適化の手法の一つです。損失が最小となるようパラメータを最適化します。パラメータを更新する過程で算出されるのが、勾配です。この勾配が小さければ小さいほど損失が少なくなります。
そこで勾配が小さくなる箇所を見つけるためのアルゴリズムの一つが最急降下法です。
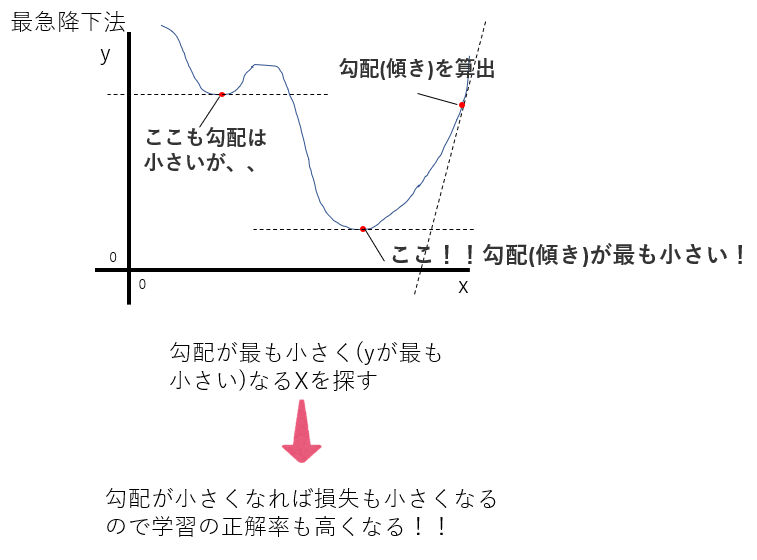
グラフだと一目瞭然で勾配がわかるのですが、これが4次元、5次元など可視化が難しくなるので理解も難しくなりますね、、
最急降下法にも様々な問題があります。全てのデータで勾配を計算するため、時間がかかる。勾配が小さい箇所が2か所以上あると、誤ったパラメータで更新してしまう(勾配から抜けられない)。最初に勾配を求めたX座標からどの程度離れて再度、勾配を計算するか?(このどの程度離れるかを学習率といいます)。
これらの問題を解決したアルゴリズムがAdamです。詳しい説明は省きますが、画像の分類だけでなく最近の最適化アルゴリズムではAdamがよく使われています。
まとめ
機械学習を0から勉強して画像判別のモデルまで作成しました。モデル作成自体はすぐできましたが、中身が全然理解できていませんでした。勉強を始めてからこの記事を書くまでに4か月くらいかかりました。正直、今でも理解できていませんwww入力情報に応じて畳み込み処理やMaxPoolingなどを組み合わせればいいと思いますが、できる気がしない、、、私の個人的な見解ですが、機械学習を仕事にするのは難しいなぁ、、趣味でモデルを作るくらいがちょうどいいかもです。次はGANとかやってみようかなぁ、
ちなみに作成したモデルに涼宮ハルヒの画像を判別させたら「みずき」と判定しました!まぁ似てるし、、当然か!